

Replication vs. Sharding: Stop Confusing Them
#EP 29 | One Scales Reads. One Scales Writes. Here's the Difference.

“Last week, someone in our Slack asked: ‘Should we shard or replicate?’
Wrong question. You probably need both. Here’s why
These aren’t interchangeable tactics. They solve different problems. Here’s what you actually need to know.
In case you want to know what Sharding and Partitioning is check this out:
Sharding vs. Partitioning: Database Magic

Picture this: your app’s database as a librarian juggling thousands of books. As users pile in, it slows down, and nobody’s happy. Ever wonder how apps like Netflix or Amazon stay lightning-fast with millions of users? They use sharding and partitioning
Sharding vs. Partitioning: Database Magic
TL; DR for the Impatient:
Replication = photocopy your DB (scales reads)
Sharding = split your data across servers (scales writes)
Together = fault-tolerant, scalable, and more complex
Replication: Scaling Reads, Not Writes
Think of replication as photocopying your database. You’ve got one source of truth (the leader/master), and you’re making copies (replicas) that clients can read from.
What it solves:
Read-heavy workloads crushing your primary
Geographic distribution (put replicas closer to users)
Fault tolerance (if the leader dies, promote a replica)
What it doesn’t solve:
Write bottlenecks. All writes still funnel through one leader.
Storage limits. Every replica holds the full dataset.
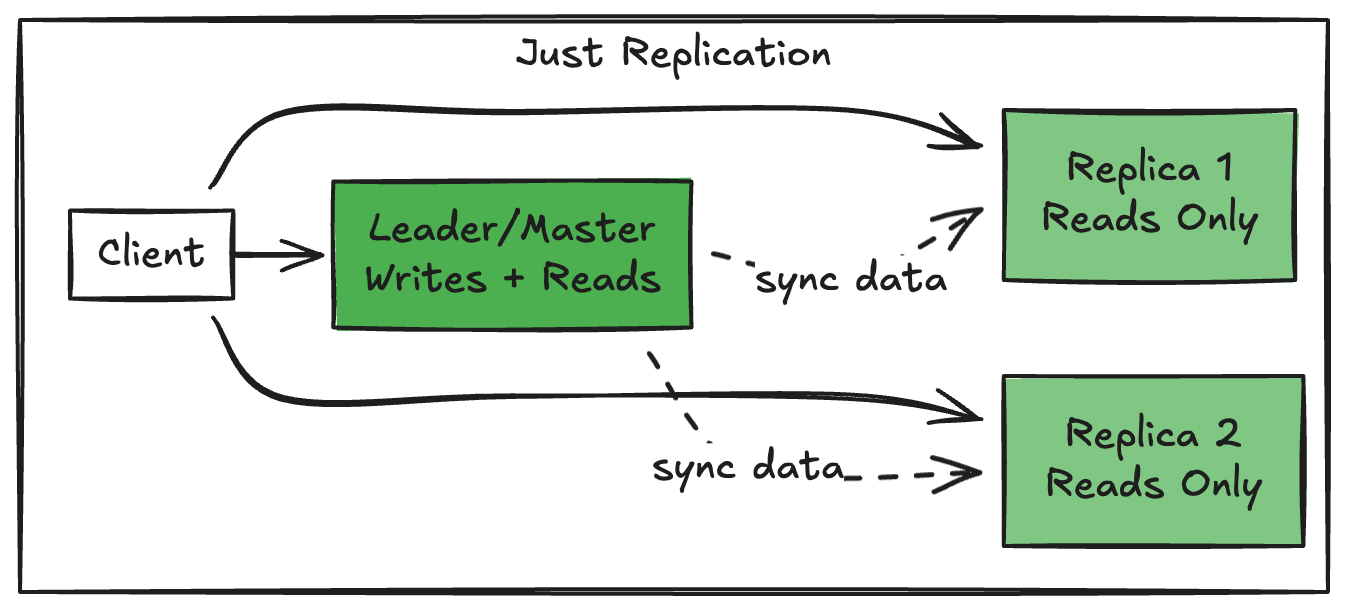
The catch: Replication lag is real. Your replicas are eventually consistent. If you read immediately after a write, you might get stale data. Plan for it.
Sharding: Splitting the Table Horizontally
Sharding is splitting your dataset across multiple independent databases. Same schema, different rows. User IDs 1-1M on Shard A, 1M-2M on Shard B, etc.
What it solves:
Write scaling. Each shard handles its own writes independently.
Storage limits. No single machine needs to hold everything.
Hotspot isolation. One celebrity user’s activity doesn’t crater your entire DB.
What it doesn’t solve:
Cross-shard queries. Joins across shards. Good luck. You’re doing that at the application layer now.
Rebalancing pain. Your shard key better be good, because changing it later is brutal.
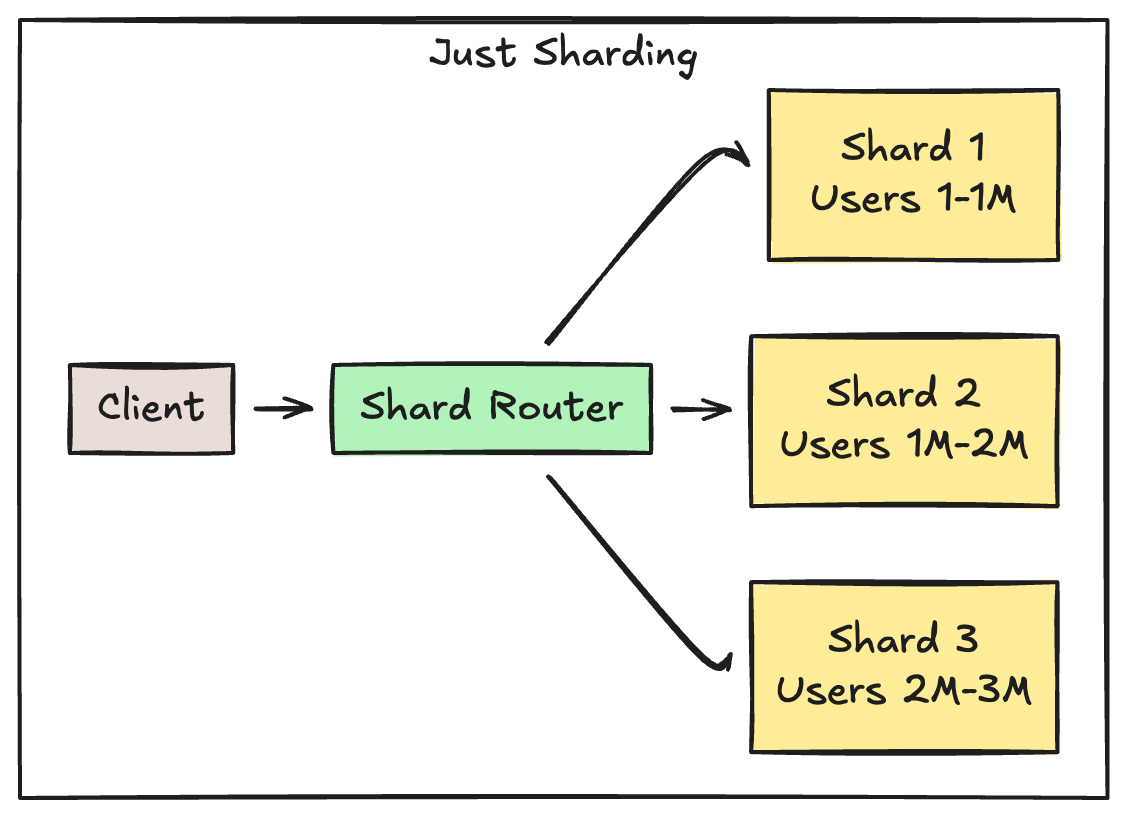
The catch: You’ve traded database complexity for application complexity. Your app now needs to know which shard to hit for every query.
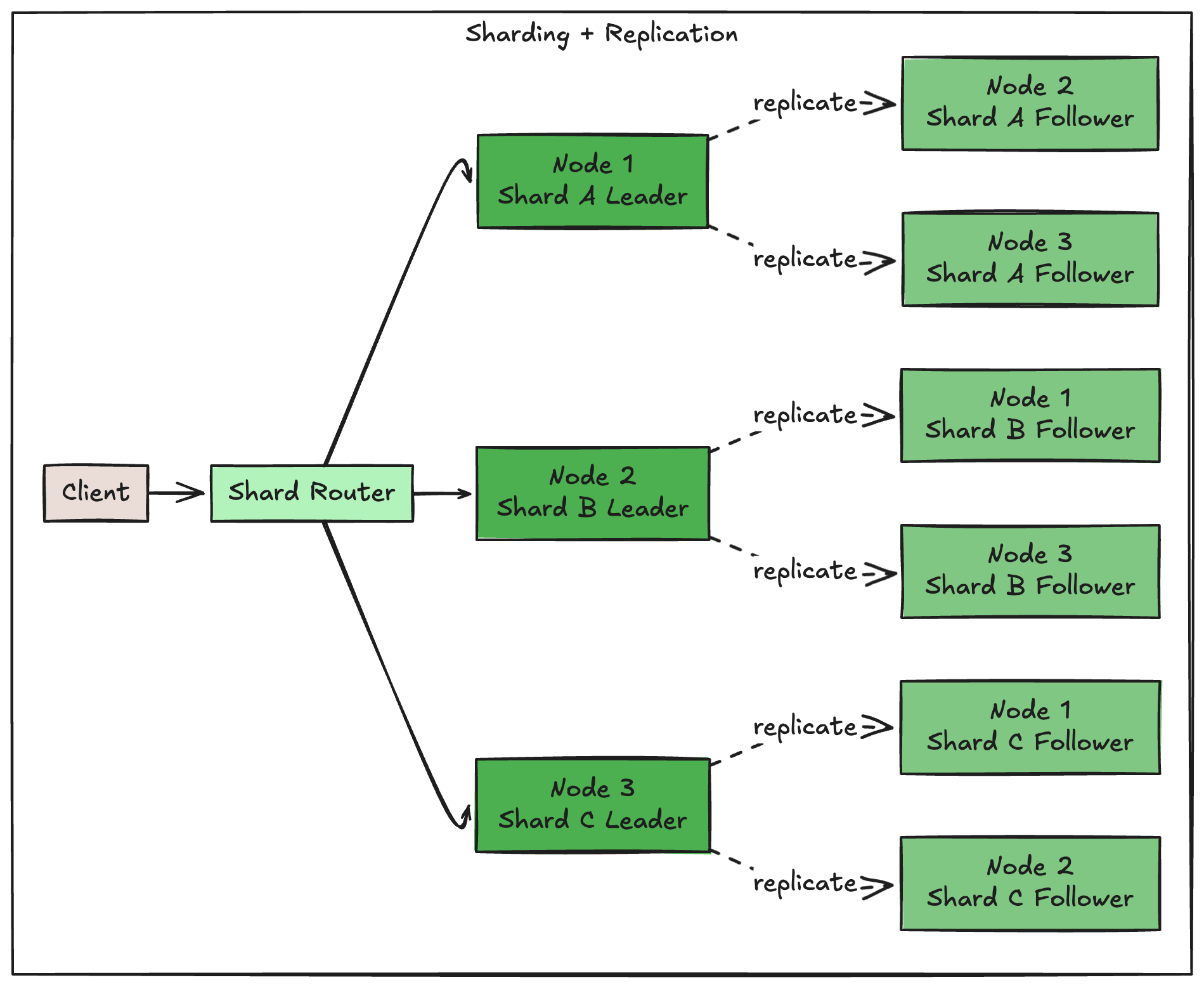
Using Them Together (And Why You Should)
Here’s where it gets interesting. Sharding + replication = a system that can handle both read and write scale while staying available.
The pattern:
Shard your data by some key (user_id, tenant_id, geography)
Replicate each shard across multiple nodes
Each node acts as leader for some shards, follower for others
Why this works:
Write capacity scales with number of shards
Read capacity scales with number of replicas per shard
If a node dies, its shards can fail over to replicas on other nodes
You’ve eliminated single points of failure
Real-world example:
Discord shards their message data by channel ID and replicates each shard 3x. When a node goes down, they promote a replica and keep serving requests. Users in that channel might see a few seconds of lag, but they don’t see downtime.
Uber shards ride data by city + time window. When you request a ride, the app knows exactly which shard to hit based on your location. Cross-city queries? They batch them async and don’t block the user.
When to Reach for Each
Just replication:
You’re read-heavy (10:1 read/write ratio or higher)
Your dataset fits comfortably on one machine
You need geographic distribution
You’re okay with eventual consistency on reads
Just sharding:
Rare in practice. If you’re sharding, you probably want replication too.
Maybe: You’ve got write pressure but zero read load (logging/analytics pipelines?)
Both:
You’ve outgrown vertical scaling
Writes are causing contention
You need high availability with no Single point of failure
You’re building for multi-region or multi-tenant workloads
The Tradeoffs Nobody Mentions
Replication lag is a feature, not a bug. Use it. Route analytics queries to replicas. Keep transactional reads on the leader. Don’t fight it.
Shard keys are forever. Choose wrong and you’ll spend months migrating data. Consider: cardinality, access patterns, and hotspot risk. User ID? Fine. Timestamp? Disaster.
Monitoring gets complicated. You’re not watching one database anymore. You need per-shard metrics, replication lag dashboards, and alerts for shard imbalance. Budget time for observability.
When to Stay Simple (AKA Don’t Over-Engineer)
You don’t need this if:
Your DB is under 100GB and growing slowly
A single postgres instance handles your load fine
You’re pre-product-market-fit and might pivot
Your team has never operated a distributed system
Vertical scaling (bigger machine) is underrated. Max out that path first.
One More Thing
If you’re pre-scale and considering this architecture “just in case,” don’t.
Replication is easy to add later.
Sharding is not.
Start simple, measure, and scale when you have real data showing you need it.
We’ve all been in the room where someone argues for sharding on day one because “we might need it.” That person hasn’t run a 3am rebalancing job yet.
Build for today’s problem. Architect for tomorrow’s.
Slow apps killing your projects? Grab my Cache Rules Everything: A Developer’s Guide to Faster Applications for pro caching techniques that 10x speed. Get it now. Peek at my top 3 optimisation hacks for more dev wins!
Creators: Want to reach an engaged audience of developers? Email me at souravb.1998@gmail.com for collaboration or sponsorship opportunities.
Help Us Shape Core Craft Better
TL; DR: Got 2 minutes? Take this quick survey to tell us who you are, what you care about, and how we can make Core Craft even better for you.
Thank You for Reading!
Loved this? Hit ❤️ to share the love and help others find it!
Get weekly tech insights to code smarter and build your dev career. Subscribe to Core Craft for practical tips and frameworks you can use today.
Have ideas or questions? Drop a comment—I reply to all! For collabs or newsletter sponsorships, email me at souravb.1998@gmail.com